Self-Attention: The Secret Sauce Behind Transformers and LLMs


In the realm of artificial intelligence, Transformers and Large Language Models (LLMs) like GPT-4 have revolutionized natural language processing. At the heart of these models lies a mechanism known as self-attention, which allows them to process and generate human-like language. But what exactly is self-attention, and why is it so powerful?
What is Self-Attention?
Self-attention is a mechanism that allows a model to weigh the importance of different words in a sentence relative to each other. It enables the model to capture relationships between words, regardless of their position in the sequence.
For example, in the sentence:
“The cat sat on the mat because it was tired.”
The word “it” refers to “the cat.” Self-attention helps the model understand this relationship by assigning higher weights to relevant words when processing each word.
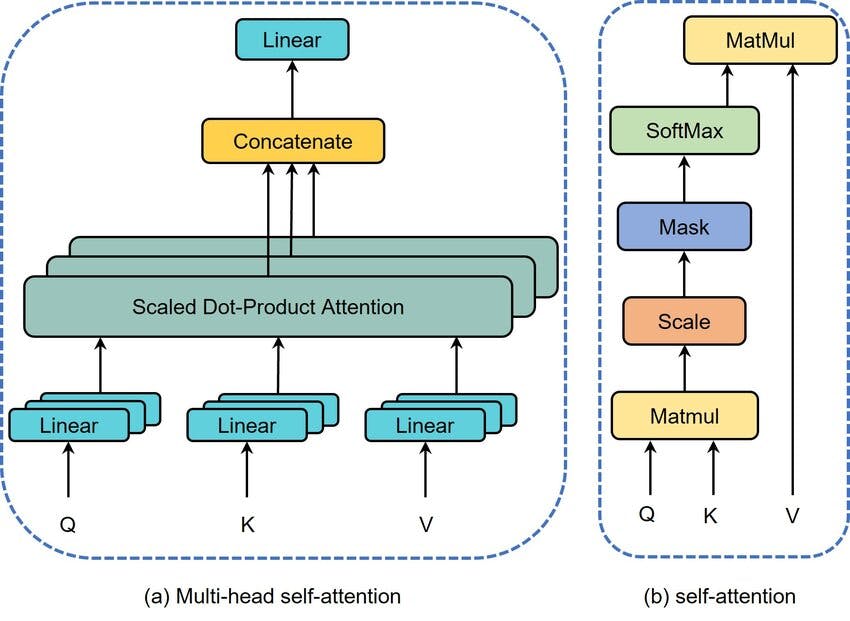
How Does Self-Attention Work?
The self-attention mechanism involves the following steps:
- Input Representation: Each word in the input sequence is converted into a vector representation.
- Query, Key, and Value Vectors: For each word, three vectors are computed:
- Query (Q)
- Key (K)
- Value (V)
3. Attention Scores: The attention score between two words is computed by taking the dot product of their Query and Key vectors, followed by scaling and applying a softmax function to obtain weights.
4. Weighted Sum: Each word’s output representation is the weighted sum of the Value vectors of all words, using the attention weights.
This process allows the model to focus on relevant words when encoding each word’s representation.
Advantages of Self-Attention
- Parallelization: Unlike RNNs, self-attention allows for parallel processing of sequences, leading to faster training times.
- Long-Range Dependencies: It effectively captures relationships between distant words in a sequence.
- Contextual Understanding: By considering the entire sequence, it provides a richer understanding of context.
Self-Attention in Transformers and LLMs
Transformers utilize self-attention in both their encoder and decoder components. In LLMs, stacked layers of self-attention allow the model to build complex representations of language, enabling tasks like translation, summarization, and question-answering.
Real-World Applications
- Machine Translation: Accurately translating sentences by understanding context.
- Text Summarization: Generating concise summaries of long documents.
- Chatbots and Virtual Assistants: Providing coherent and context-aware responses.
Conclusion
Self-attention is a fundamental component that empowers Transformers and LLMs to process language with remarkable proficiency. Its ability to model relationships and context has paved the way for significant advancements in natural language processing.